Le forum PHP 2022 à DisneyLand
Un moteur bien huilé – Thibault RICHARD – Wid’op
Thibault nous présente le design pattern Rule Engine au travers un retour d’expérience chez un client dans le domaine du logement social. Un client donc qui possède donc un métier complexe avec beaucoup de règles et de traitements différents.
Rule Engine est un système qui évalue un ensemble de règles métiers et détermine les actions à réaliser. Cela permet d’éviter les successions de if / else if dans un algorithme complexe possédant de nombreuses conditions.
Ce modèle est découpé en deux entités : les règles (Rule) et le système qui évalue ces règles, le moteur (Engine).
Ainsi, comme le présente Thibault dans un exemple d’algorithme chargé de lister une collection de documents administratifs à fournir par un demandeur selon ses critères de nationalité, de situation professionnelle etc.
public function getDocuments(User $user): array
{
$documents = [];
if ($user->isFrench()) {
$document[] = new Document('piece d\identité')
} else {
$document[] = new Document('titre de séjour');
}
if ($user->isEmployee()) {
...
}
}
On peut facilement transformer chaque if par une règle métier tel que
class IdentityRule implements RuleInterface
{
public function when(User $user): bool
{
return $user->isFrench();
}
public function then(User $user): Document
{
return new Document('Piece d\'identité');
}
}
Enfin, il restera à créer la classe DocumentEngine prenant en paramètre la liste des règles dans un tableau, puis itérer sur chaque règle pour vérifier si lorsque when retourne vraie, alors on appelle then, le traitement de la règle – dans notre exemple si le demandeur est Français, la règle retourne la demande de document “Pièce d’identité”.
Thibault nous dévoile comment avec Symfony, il est arrivé facilement à brancher ses règles avec ses moteurs via l’injection de dépendance par tag. Il suffit de tager les règles puis de les injecter dans un itérateur avec tagged_iterator, voir la documentation Symfony pour en savoir plus.
Cette conférence tombe à pic pour nous chez AKAWAKA. En effet, nous avons actuellement un client qui veut refondre un intranet BtoB possédant un métier très complexe avec beaucoup de conditions.
Nous avons tout naturellement repris ce modèle, cependant, en allant un peu plus loin dans l’implémentation. Nous avons en plus inclus le design pattern spécification qui isole le if dans une classe dédiée, ce qui permet de réutiliser cette condition partout dans notre application.
Enfin, nous avons ajouté du log informatif dans nos moteurs, permettant de suivre les règles qui s’applique ou celles qui sont ignorées. Dans un contexte de refonte d’une application vieillissante, cela nous permettra d’identifier les règles qui sont très peu, voire jamais appelées.
class WhenUserHasFailureStatus implements RuleInterface
{
public function __construct(
private DoUserHasFailureStatusInterface $doUserHasFailureStatus
) {}
public function when(User $user): bool
{
return $this->doUserHasFailureStatus->isSatisfiedBy($user);
}
public function then()
{
...
}
}
abstract class AbstractEarlyRuleEngine implements RuleEngineInterface
{
private iterable $rules = [];
private InstrumentationInterface $instrumentation;
public function __construct(
iterable $rules,
InstrumentationInterface $instrumentation
) {
$this->rules = $rules;
$this->instrumentation = $instrumentation;
}
/**
* @throws RuleEngineException
* @throws RuleException
*/
public function __invoke($subject)
{
$this->instrumentation->start($this);
/** @var RuleInterface $rule */
foreach ($this->rules as $rule) {
if ($rule->when($subject)) {
$this->instrumentation->match($this, $rule);
try {
$result = $rule->then($subject);
$this->instrumentation->success($this, $rule, $subject);
return $result;
} catch (\Exception $exception) {
$this->instrumentation->error($this, $rule, $subject, $exception->getMessage());
throw new RuleException($exception->getMessage(), $exception->getCode(), $exception);
}
} else {
$this->instrumentation->skip($this, $rule);
}
}
return null;
}
}
Avec le service Instrumentation qui va se charger de loger les interactions en allant piocher dans nos classes de règle et de moteur du contexte via une méthode getDescription. Ce qui donne au final
[2022-10-21T14:56:47.044789+00:00] app.INFO: security.user_verification.rule_engine.start {"engine":"User verification depends specific rules"} []
[2022-10-21T14:56:47.044874+00:00] app.INFO: security.user_verification.rule_engine.skip {"rule":"When A, then a"} []
[2022-10-21T14:56:47.044941+00:00] app.INFO: security.user_verification.rule_engine.match {"rule":"When B, then b"} []
[2022-10-21T14:56:47.044998+00:00] app.INFO: security.user_verification.rule_engine.success {"rule":"When B, then b","data":{"user":"00012345"}} []
Sauve un-e dév, écris une doc ! – Sarah HAÏM-LUBCZANSKI – Bedrock
La documentation d’une application, son fonctionnement, son code a toujours été un sujet compliqué. Quoi documenter ? Comment présenter cette documentation ? Tout un tas de questions auxquelles Sarah tente de répondre dans sa conférence.
Elle nous liste des conseils, des outils et des exemples très pertinents, mais aussi ce qu’il ne faut pas faire ; non, la documentation dans le code n’est pas une bonne documentation.
Elle s’appuie sur le framework Diátaxis qui range selon le niveau de maîtrise et d’attente du lecteur, les type de documentations possibles : les tutoriels (orienté apprentissage), les guides (orienté réalisation), les explications (orientée compréhension) et les références (orienté information technique).
Quant à la forme, des outils permettent de savoir comment bien présenter et tenir une documentation, tels que https://www.writethedocs.org/ qui est une documentation sur la manière d’écrire de la documentation, ou bien https://github.com/ddbeck/readme-checklist qui est une checklist aidant à bien rédiger votre README.
Enfin, elle nous prévient cependant que vouloir faire des documentations dynamiques avec une UX avancée à la Stripe demande du temps et des ressources. Chez Stripe, c’est une équipe de 30 développeurs / rédacteurs qui sont à l’œuvre. De plus, une documentation ça doit être chérie. Il faut la garder à jour, l’enrichir d’exemples, d’images et de schémas quand c’est pertinent.
En bref, une bonne documentation, est un outil qui fait gagner du temps, mais il faut respecter quelques règles pour que celle-ci soit utile. Alors pourquoi ne pas prendre tout de suite les bons réflexes ?
Une extension PHP rouillée – Pierre TONDEREAU – Mention
Dans cette conférence, Pierre nous présente un REX de création d’extension en Rust.
De par ses grandes performances (proche du C) et sa syntaxe digne d’un langage de haut niveau, Rust est un allié de choix.
Il intègre sur son projet la gestion d’algorithme redlock sur Redis via une extension qu’il a conçu https://github.com/ptondereau/ext-redlock-php. PHP grâce au FFI peut exécuter du C et donc du Rust.
L’intégration est simplifiée pour les extensions grâce à ext-php-rs https://github.com/davidcole1340/ext-php-rs. Ce package a pour but de rendre la création d’extension plus simple grâce à la documentation fournie de Rust, ses fonctionnalités modernes, tout en permettant une gestion plus large de versions PHP. Puisque le code Rust est transformé, il va être capable de fonctionner en versions PHP plus anciennes et futures selon le support de l’extension.
De l’humain à l’ordinateur, ou découvrir le sens d’un texte avec ElasticSearch – Mathias ARLAUD – Les Tilleuls
Mathias ARLAUD nous a montré à travers sa conférence comment Elasticsearch (grâce Apache Lucene) pouvait, à partir d’un simple mot, effectué une recherche intelligente sur tout un ensemble de documents.
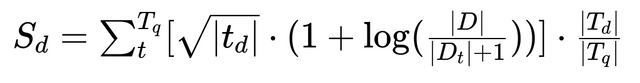
Cette équation peut faire peur, mais Mathias a su nous l’expliquer en la simplifiant sous la forme :
Sd = (TF * IDF) * C
Où :
- TF représente le
termFrequency. C’est-à-dire le nombre de fois où le mot recherché est présent dans les documents stockés dans Elasticsearch. - IDF représente l’
ìnverseDocumentFrequency, qui va déterminer si oui ou non le mot d’une phrase recherché est pertinent. - C représente le
coordinationFactor. Ce facteur de coordination va mettre en avant les documents contenants le plus haut pourcentage de mots présents dans la phrase recherchée.
Seulement cette formule ne suffit pas à obtenir des résultats pertinents. En effet, Elasticsearch va venir appliquer un traitement en trois étapes au moment de la recherche.
En premier interviennent les filtres de caractères, qui auront la responsabilité d’ajouter, de modifier ou de supprimer des caractères de la phrase recherchée en fonction de règles prédéfinie (pattern_replace, html_strip, etc.)
Arrivent ensuite les générateurs de tokens. La recherche Elasticsearch ne se base pas sur des mots, mais sur des token. Elasticsearch va donc utiliser des générateurs pour découper la requête en token.
Enfin, les filtres de tokens vont venir agir sur ces tokens pour les modifier. Il en existe plusieurs, dont :
stopwordqui permet de supprimer tous les tokens inutiles tels quele,la,lesstemmerqui va appliquer une série de règles, afin d’obtenir la forme dite “canonique” d’un token, les regroupant ainsi selon cette forme. Par exemple, si nous appliquons ce filtre aux tokens suivant :développement,développeuretdéveloppeusenous obtiendronsdévelopp,développetdévelopp.
Pour conclure, Mathias ARLAUD à su nous ouvrir les portes d’Elasticsearch et d’Apache Lucene pour nous montrer comment, à partir d’une “simple” équation et de quelques outils, Elasticsearch réalise ses recherches de manière intelligente.
Comment être bien onboardé en tant que développeuse junior reconvertie ? – Amélie ABDALLAH – TheTribe
Amélie ABDALLAH nous a raconté son histoire de développeuse reconvertie. À travers cette conférence, elle souhaitait faire passer un message à toutes les entreprises présentes.
Recruter des profils en reconversion et donc junior !
Lors de son parcours pour devenir une développeuse accomplie, Amélie est passée par des obstacles :
- une entreprise pas disponible pour l’aider dans son apprentissage
- une pression due à sa reconversion
- une alternance à ne pas louper
- commencer à coder le premier jour sans soutien ni documentation à l’appui
Pour surmonter ces obstacles, elle a décidé de changer d’entreprise et ce fût une idée qu’elle ne regretta pas. Nouvelle boîte, nouvel accueil, nouveaux collègues, nouvelle façon de faire.
C’est là qu’elle a découvert :
- une toute nouvelle procédure d’encadrement
- une présentation de toute l’équipe
- la découverte de tous les métiers
- une formation complète aux bonnes manières de coder
- que coder le premier jour n’est pas bénéfique à l’apprentissage
En conclusion, dans cette nouvelle entreprise, elle a eu tous les outils nécessaires pour débuter sa nouvelle carrière de développeuse.
Aujourd’hui, elle est épanouie dans ce qu’elle fait et elle souhaite que chaque développeur junior ait la chance d’avoir un accompagnement comme le sien.
FFI : De nouveaux horizons pour PHP – Pierre Pelisset – Karafun
C’est lors du développement de leur solution de boxs karakoé que Pierre et son équipe ont été confronté à un dilemme : continuer à utiliser une librairie Python (PySerial), qui posait des soucis techniques et n’est plus mise à jours depuis 2020 ? Ou bien utiliser pleinement PHP et ses fonctionnalités pour communiquer directement sur les ports RS-232 des boxs ? C’est cette seconde solution qui a été choisie et Pierre nous a présenté FFI (disponible depuis la 7.4), fait un retour d’expérience de son usage au travers de quelques cas simples mais concrets.
FFI permet donc de pouvoir utiliser au sein de son code PHP d’autres langages. D’exploiter leur spécificité. Sans rentrer dans des détails trop techniques ici, il s’agit de pouvoir utiliser des bibliothèques compilées (.dll sous Windows ou .so sous Linux) en les chargeant dans notre contexte PHP grâce à C et quelques définitions.
Pour résumer nous devons écrire un simple header en C contenant les définitions des méthodes que nous utiliserons ensuite. Puis nous chargeons ensuite cet header et la librairie associée, rédigeons une sorte de mapping entre les types C et nos types PHP (grâce à des méthodes spécifiques à FFI), puis une ou des classes qui vont intégrer les appels aux méthodes de la librairie. Selon les retours de Pierre nous pouvons utiliser FFI en production. C’est ce qu’ils font pour remplacer leur code python et pouvoir directement communiquer sur les ports RS-232 en PHP. Toutefois FFI ajoute une couche supplémentaire qui, selon les cas, peut poser des soucis de performance. L’usage doit donc être réfléchi et le gain notable pour basculer dessus. De même que quelques notions en C sont nécessaires (pour l’écriture des headers et le typage), même si ce sont des notions assez basiques (pointeurs, etc.).
FFI est une solution intéressante qui peut mériter que l’on s’y penche dans certains cas (souvent des environnements multi-langages ou ayant des besoins très spécifiques). Il ouvre le champ des possibles à PHP en plus de rattraper, une fois de plus, son retard sur d’autres langages de programmation qui intègrent FFI depuis de nombreuses versions.
Du TensorFlow depuis PHP devient alors possible… sans extension 🙂
Revue de code : on n’est pas venu pour souffrir ! – Anne-Laure de Boissieu – Bedrock
Ayant intégré Bedrock, il y a de cela quelques mois à peine, Anne-Laure était quelque peu anxieuse quant aux retours qu’elle pourrait avoir lors de ses merge requests. En effet, un malentendu à l’écrit peut arriver (et nous est tous déjà arrivé au moins une fois). Un commentaire anodin peut alors avoir un impact bien plus important que ce que l’on imaginait auprès de son interlocuteur, selon la tournure de phrase choisie, les mots employés, etc.
Mais Anne-Laure a découvert un cadre rassurant qui permet d’éviter ce genre de déboire. L’équipe se base sur le conventional comments afin de normaliser les réponses (dans la même idée que le conventional commits pour nos commits), expliciter l’intention et éviter au maximum toute forme de malentendu sur les reviews.
Le résultat final permet une prise de confiance et un onboarding facilité selon elle. Tout en améliorant la qualité globale du projet grâce à une communication saine et sans ambiguïté (ou tout du moins réduite au minimum). Ce à moindres frais puisque l’adoption de cette règle est facilitée par l’existence d’extensions de navigateur (sous Chrome et Firefox).
Un pas de plus vers une communication bienveillante au sein des équipes.
Watch the clock – Andreas HEIGL – stella-maris.solutions
Dans sa conférence, Andreas Heigl nous parle de temps et comment le maîtriser notamment pour lors de tests. En effet, la fonction time() en PHP est une fonction impure et donc elle ne renvoie pas toujours la même valeur. Un code qui utilise cette fonction est difficilement testable, car son résultat peut varier.
Pour palier à ces soucis, Andreas nous propose d’utiliser une interface pour récupérer le temps dans nos applications.
<?php
namespace Psr\Clock;
interface ClockInterface
{
/**
* Returns the current time as a DateTimeImmutable Object
*/
public function now(): \DateTimeImmutable;
}
Comme l’espace de nom l’indique, cette interface est une PSR (la PSR-20), celle-ci est actuellement en brouillon.
L’interface peut ensuite être implémentée pour renvoyer le “vrai” temps ou alors pour renvoyer un résultat déterministe pour nos tests.
Cette solution permet d’isoler les appels aux fonctions impures. Finit les tests flacky !
The PHP Foundation: The past, the present, and the future – Sebastian BERGMANN – thePHP.cc / Roman PRONSKIY – JetBrains
PHP, malgré son long historique n’a pas de fondation officielle avant 2021 (?). Le besoin est apparu rapidement dû au bus factor mais s’est amplifié, notamment à cause du départ de Nikita Popov. Il arrête d’investir du temps à PHP pour se consacrer à LLVM au 1er décembre 2021. De nombreuses organisations se sont joint afin de lancer officiellement PHP foundation dans le but de maintenir la pérennité du langage. L’usage des fonds est publique et sert à missionner des développeurs, à temps pleins ou occasionnellement. Elle ne vise pas à prendre un monopole décisionnel, ne souhaite pas s’impliquer dans les RFC et laissant à la communauté PHP Internals les décisions d’évolutions du langage. On retiendra de la conférence qu’il est important que les entreprises qui utilisent tous les jours ce langage contribuent à sa pérennité.
Cette solution permet d’isoler les appels aux fonctions impures. Finit les tests flacky
Un grand merci à l’AFUP d’avoir organisé ce forum exceptionnel.
Nos derniers articles